机器学习之:机器学习引导
简介
要问2022年什么最火,那莫过于人工智能了。人工智能提了几十年,早在科幻电影中我们就描绘了诸多比人还聪明的机器。什么终结者、超体、攻壳机动队等等都离不开人工智能的影子。在我们的想象中,人工智能是一种人类制造出来的,会自主学习的比人类还聪明的机器。很可惜的是,虽然我们也一直会讨论到底人还是AI才是未来世�界的主人,但是AI好像一直都存在于我们的想象中,离人类真实的世界还很远。
也许AlphaGo的获胜让大家在感到惊奇的同时又有点理所当然,那么由波士顿动力学工程公司设计的机器狗和机器人就让人有点担忧了。看完机器人的街舞表演,你还认为人工智能的时代离我们还远吗?
虽然我们不能够预测未来人工智能能够发展到哪一步,但是现在停下来了解下人工智能的底层原理会不会对我们在未来的生存提供一丝丝帮助呢?好了,现在我们进入人工智能的基础机器学习的世界。
顾名思义,机器学习就是使用机器来进行学习,机器指的是计算机,学习指的是学习历史事件的规律,从而能够在特定的环境中进行反应或者行为预测。机器学习是包括计算机科学,工程技术学,统计学概率论等多个学科的综合体。大数据是机器学习的基础。机器学习可以从海量的数据中使用一定的算法,从而将无序的数据转换成为有用的信息。
机器学习的应用场景
上面我讲到了,机器学习就是使用机器根据历史数据来学习一定的规律,从而对未来发生的事情进行一个预测或者判断。所以机器学习需要学习大量的历史数据,这就是学习一词的来历。
为什么会有机器学习呢?我们先来考虑一个科幻场景。如果要你来制作一个机器人你会怎么做?
大家可能会首先想到,制作一个机器人的框架,这个机器人有手有脚,可以活动,还可以卖萌。高级点的,可能想到这个机器人能不能像变形金刚那样能够变形。
很好,上面大家已经实现了一个机器人玩具。但是这个机器人没啥实际意义,只能当做玩具。能不能智能一点呢?
我们尝试着给它套上一套软件,用软件来控制他的前进后退。这就是遥控机器人了。这个机器人已经比较智能了,但是还完全控制在遥控器的手上。
我们更进一步,这个机器人能不能自己根据外界的环境来做相应的行动?先来一个简单点的场景,我们可能把历史数据存到机器人的电脑里面,如果遇到场景和历史场景一样的情况,就做出相应的行动。这样就实现了一个基本的人工智能。
再进一步,如果遇到的场景和历史场景有一些差别,机器人的电脑能不能识别这些场景,进行采取正确的行动?
最后,如果遇到额场景和历史场景完全不同,机器人又如何去响应呢?
作为一个程序员,我们是怎么解决这个问题呢?最简单的可能就是通过各种if else的决策规则来进行数据的处理。如果决策场景比较多,还可以设计一个规则体系模型。但是这些人为的制造规则存在着一些问题:第一个问题是决策规则使用的范围比较窄,如果任务有变化,那么需要重写整个逻辑。第二个问题是要想正确的制定决策,需要对整个过程有深入的理解。还有一个问题是,人类决策的方式和计算机决策的方式是完全不同的,比如在图像识别领域,计算机能够识别的只是像素,这个和人类的感知方式是完全不一样的,从而导致人类制定的规则可能无法在计算机中应用。
所以我们需要一种机器学习的方法,来帮助人们进行场景识别和预测。
目前机器学习的应用非常广泛,比如垃圾邮件判断、医学影像识别、信用卡交易欺诈识别、证券市场分析、计算机视觉等方向。
机器学习的主要任务和算法
机器学习之所以能够替代人类进行信息决策,是因为底层使用的优秀算法。机器学习的主要任务有四种,分别是:分类、回归、聚类和密度估计。根据是否有确定的目标值,可以将机器学习的算法分为监督学习和非�监督学习两种。
先看一个这些算法的总体描述图:
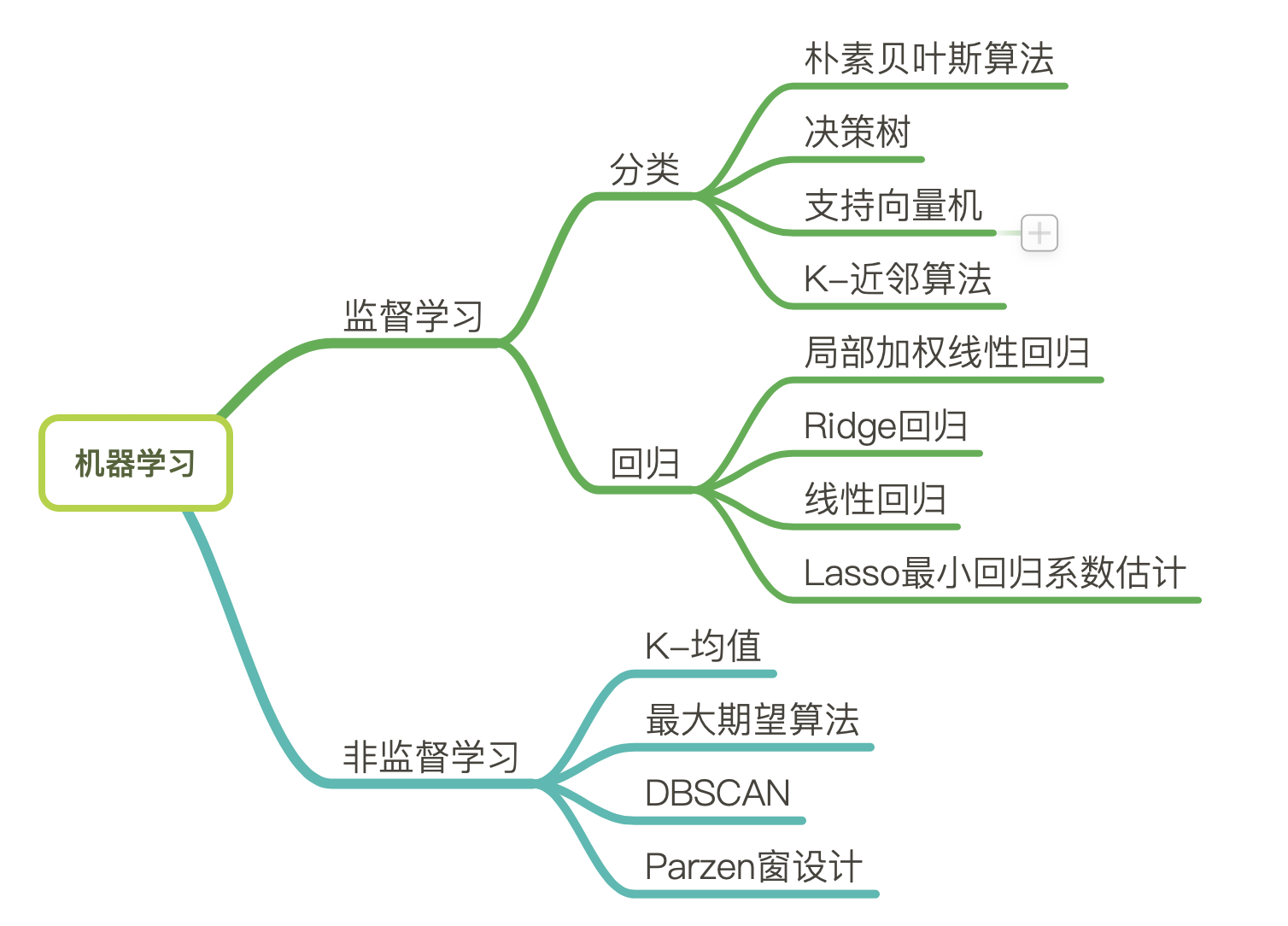
监督学习
监督学习就是说学习的历史数据中有输入也有输出。在决策过程中,通过提供给算法历史的输入和输出数据,算法会找到一种方法,根据给定的输入给出预测的结果。算法的高明之处在于,即使给出的输入值在历史数据中并没有出现过,算法也可以根据内在的联系去预测预期的结果。
这种算法需要通过给定的历史结果来对算法进行校正,就好像有人在监督一样,所以叫做监督学习。
监督学习比较好理解,它的常见应用就是分类和回归。
相应的因为有对应的结果,所以监督学习算法的评估就比较容易进行。只需要跟实际的结果进行比较就可以了。
非监督学习
非监督学习就是说给定的历史数据只有输入,没有输出。算法尝试在这些数据中寻找内在的规律。因为并没有输入,所以对于这种算法的评估就比较困难。
常见的非监督学习的应用包括聚类、密度估计等。
之前看过一个非监督学习的比较有趣的应用,就是分析金庸武侠小说中的人物,对这些人物进行分类等操作。因为你并不知道非监督学习到底会输出什么样的结果,所以往往会带给人不一样的惊喜。
分类
分类是监督学习的一种,目标是预测类别信息。给定的历史数据是特征信息和其对应的分类信息。通过算法训练,可以将未来的输入划分到给定的类别中。根据分类的类别个数不同,分类又可以分为二分类和多分类。
主要的分类算法包括:回归分析、决策树、人工神经网络、贝叶斯网络、支持向量机等。
回归
分类算法预测的是离散值,而回归算法预测的就是连续值。回归算法也是监督学习的一种。比如根据股票的历史走势来预测股票未来的价格。
区分分类和回归的简单方法就是看这个输出是否具有连续性。
常用的回归算法有:线性回归、非线性回归、逻辑回归、岭回归和主成分回归等。
聚类
聚类和分类有些类似,但是聚类是无监督学习方法,和分类不同的是,在聚类算法中,并没有给出最后可分类的具体数据,这一切都是由算法本身来控制的。聚类是根据数据自身的距离或者相似度来将其划分为不同的组别。划分的原则是组内的距离最小,而组外的距离最大。
常见的聚类方法包括:划分法、层次分析法、基于密度的方法、基于网格的方法和基于模型的方法等。
密度估计
密度估计也是无监督学习的一种,但是它通过样本分布的紧密程度,来估计与分组的相似性。
机器学习算法的选择步骤和原则
上面这么多算法,我们在做机器学习的过程中是如何选择的呢?
看一下机器学习算法的选择步骤和原则:
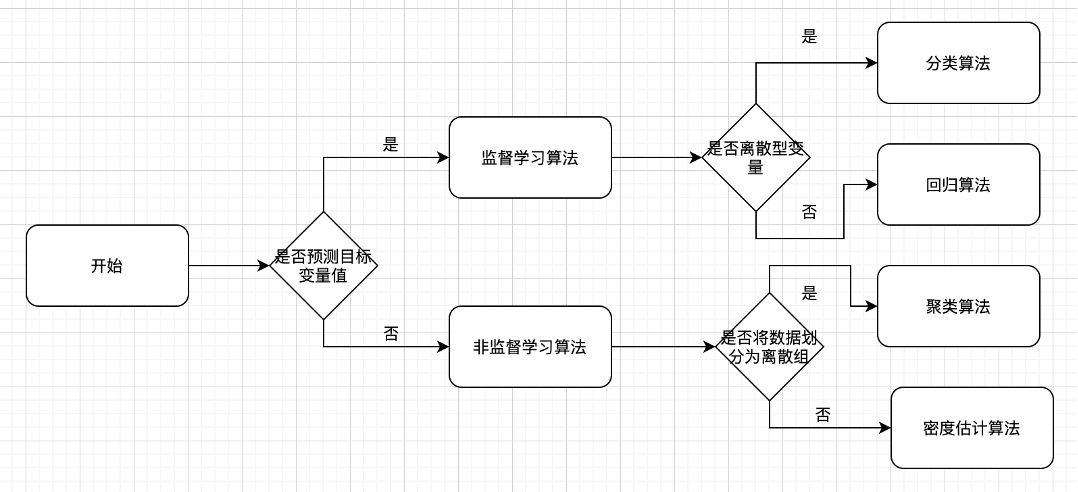
再看一个更加复杂和详细的选择图:
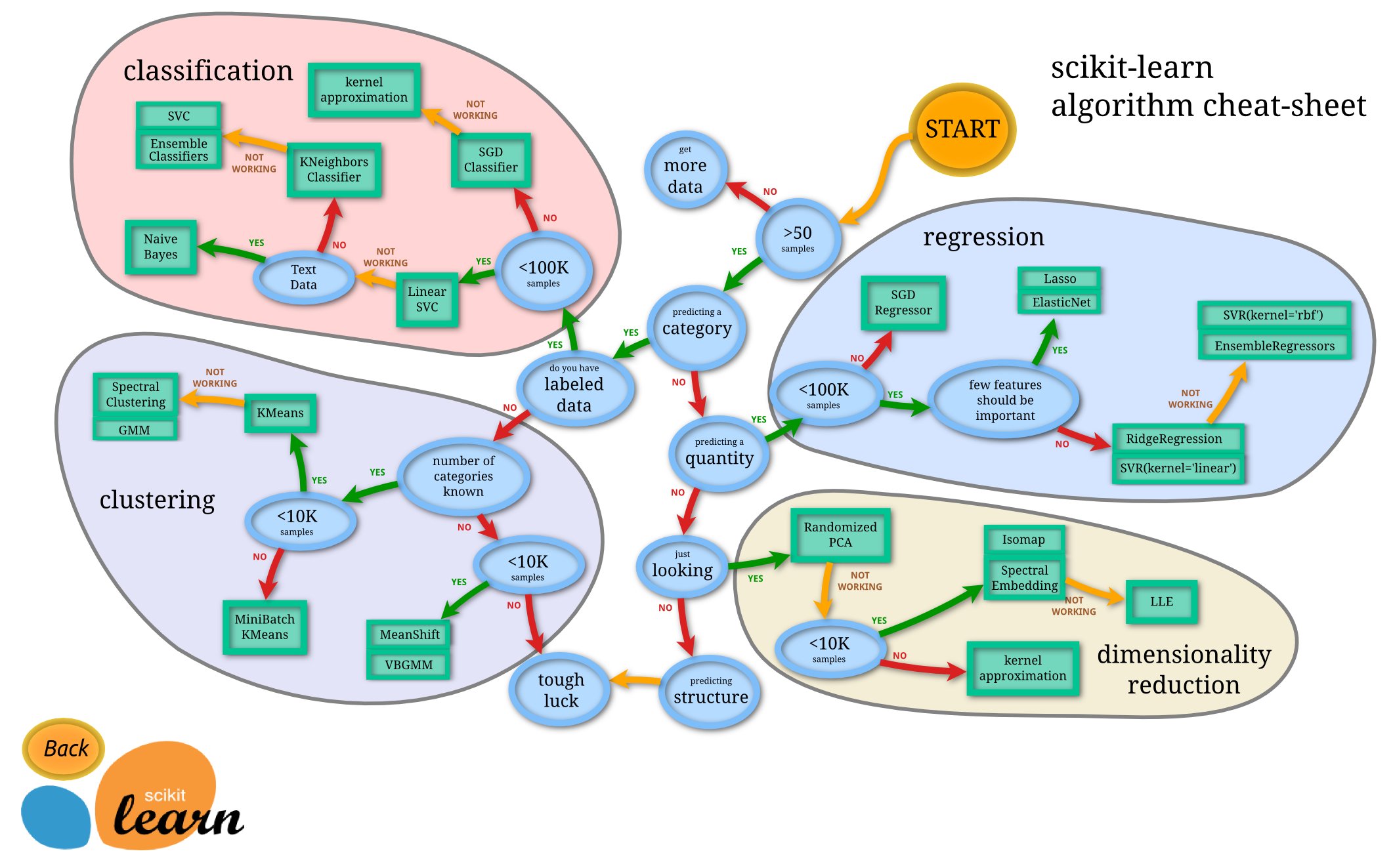
机器学习的应用步骤
选好了算法只是机器学习中一个步骤,接下来我们来看一下一个完整的机器学习的过程是怎么样的。
一般来说机器学习都可以分为以下6个步骤。
- 收集数据
机器学习的基础就是海量的数据。在收集数据阶段,我们借助大数据和爬虫之类的各种手段来收集所有可能有用的数据,机器学习将会学习这些数据中的规律,然后进行预测。
- 准备数据
在获得可用的数据之后,我们需要将其转换为计算机能够识别的数据,并规定好他们的数据格式,方便输入到计算机中。
- 分析数据
数据输入到计算机之后,需要对输入的数据进行分析。如果数据非常多的话,还需要对现有数据进行取样,找出一个和目标相关的样本数据子集。选取的标准主要是相关性,可靠性和有效性。通过对数据的选择,一方面可以减少数据的处理量提高数据的处理速度,另一方面可以消除噪声数据对目标结果的干扰。
选择完数据之后,接着就是对数据进行探索,审核和必要的加工处理。包括异常值分析,缺失值分析,周期性分析和相关性分析等。这些处理的目的是保证数据的质量,进而保证机器学习的准确性。
分析完之�后就是进行数据的预处理,包括填补数据、清楚重复数据、数据标准化、变量转换、主成分分析、数据规约等清洗、转换和重塑的操作。
- 训练算法
有了样本数据之后,就可以开始真正的机器学习了,通过将第三步的数据格式化输入到选择的算法模型中,经过不断的训练,可以得到一个训练好的模型。
- 测试算法
使用步骤4得到的模型,选择特定的数据来测试该模型的准确性。通过比较预测值和真实值的差异,可以选择重复3-4步骤来修正模型。最终得到一个在误差范围之类的模型。
- 使用算法
应用该模型,将该模型转换为应用程序,并执行实际任务,在实际任务中进一步对该模型进行检测。
机器学习的数学基础
听起来机器学习是一件很高大上的事情,那么我们在使用机器学习的过程中需要掌握什么数学知识吗?
通常来说机器学习的各种算法中可能会用到微积分、线性代数、概率论等知识。我们如果想要对这些算法有一个深刻的认识,肯定是要掌握相关的数学知识。
但是作为机器学习的应用者来说,我们并不需要深入研究这些算法的底层,只需要知道这些算法的原理,并能够应用即可。
机器学习的工具
机器学习的利器就是Python了。经过这么多年的发展,Python提供了众多的关于机器学习相关的库,非常的强大。我们可以在python中使用非常简单的代码即可以实现复杂的功能。比如数据分析的库:NumPy和Pandas,科学计算的库:SciPy等等。
好了,有了这些基础知识之后,我们就可以开始探索机器学习的世界了。
点我查看更多精彩内容:www.flydean.com

